全新版本的 Easegress 发布
Easegress v2.0 发布了,这是 Easegress 的第二个大版本,大幅增强了流量编排功能,同时也包含其它多项优化和改进。
为什么开发 Easegress
部署 Web 服务时,经常要使用流量网关做反向代理,业界也有包括 Nginx 在内的很多出色的网关产品。但这些产品诞生的时候,甚至还没有“云原生”的概念,所以,进入云原生时代之后,它们暴露出了各种不足,包括:
- 缺乏高可用部署方案
- 缺乏流量着色、动态编排功能
- 缺乏监控、服务发现等功能
另一方面,各种各样的业务逻辑的侵入,也要求系统非常容易的扩展。这方面,Nginx 使用的 C + Lua 的方式并不够好,因为 C 语言太晦涩也太容易出错,而 Lua 的表现能力又不够强大。
MegaEase 认为,云原生时代的流量网关不能仅仅是一个反向代理,必须支持动态流量编排和调度。此外,在具体应用场景中,还必须高度可扩展,以应对各种各样的业务逻辑侵入。
基于以上观点,MegaEase 开发了新一代流量型网关产品——Easegress,这个产品完全架构于云原生之上,避免了传统反向代理的不足,具有云原生、高可用、动态流量编排、可观测、可扩展等特点。尤其可扩展性,Easegress 在多个层面进行了针对性的设计。
首先,在开发语言的选择上要选择易于使用的语言,对比 C、C++、Java、Rust、Go 等主流静态语言后,我们认为Go 兼具简单易用和性能优异两大优势,所以,Easegress 最终选择了 Go 作为开发语言。但不管使用什么语言,源码级的扩展都不可避免的将用户限制到一门特定的语言,而且会涉及重新编译、重新布署、重新启动,造成服务的中断。
第二,通过外部调用的方式扩展,如 FaaS。FaaS 方式的优势是不限制用户的开发语言,而且可以让整个架构具有良好的可伸缩性,但其缺点是需要引用 Kubernetes 等的比较重的外部依赖,导致运维工作变得非常复杂(Easegress 目前已经支持了 Knative);
第三,通过嵌入其它语言的解释器进行扩展。这方面,Lua 本身就是为嵌入其它程序而设计的,具有相应的优势。但我们认为 Lua 也有两个缺点,一是本身表现力不够,不适合写复杂的业务逻辑;二是太小众,不是主流语言,有相关经验的程序员太少。所以,经过权衡,Easegress 最终选择了嵌入 WebAssembly,主要基于两点考虑:一是接近于原生代码的高性能;二是不限制用户的开发语言,用户可以使用自己喜欢或熟悉的语言开发业务逻辑。
为什么开发 v2.0
以上这些相对于传统流量网关的改进都已经在 Easegress v1.x 版本中实现,并得到了用户的关注和好评。但随着用户的增多,新用户带来了新需求,也带来了新问题,主要包括:
Easegress 是从真实用户项目中发展起来的,所以它从诞生之日起,就在实实在在的解决用户的问题,但这也让它最初的设计和实现与具体场景贴的太近,前瞻性不足。我们知道,Pipeline 是 Easegress 进行流量编排的核心组件,但由于用户最初只使用 HTTP 协议,所以 Pipeline 也与 HTTP 紧紧的绑在了一起。这样,当需要支持 MQTT、TCP 等协议时,我们就不得不为每一种协议实现一个新的 Pipeline,这些 Pipeline 大同小异,多个不同的实现既不利于用户使用,也不利于代码维护。所以,我们需要一个协议无关的 Pipeline 实现,让它不仅支持所有协议,还支持不同协议的混合编排。
Easegress 支持 API 编排,并为此开发了包括 APIAggregator、RequestAdaptor、ResponseAdaptor 等在内的 Filter 以实现复杂的编排功能。但这些 Filter 实际上处于各自为战的状态,并不能组合在一起实现 1+1>2 的效果。比如,我们可以通过 Easegress 来读取某个博客的 RSS Feed,也可以通过 Easegress 向 Slack 发送一条消息,但却不能将二者结合起来——先读取 RSS Feed,然后把文章列表发送到 Slack。
没有明确区分控制逻辑和业务逻辑。总的来说,业务逻辑处理数据的创建、删除、修改,控制逻辑决定各种操作的执行次序。虽然二者的划分并不绝对,但在 pipeline 中,我们可以认为业务逻辑是处理 Request 和 Response,而控制逻辑是 Filter 的编排、容错处理等,所以,Easegress 中的 Filter 应该专注于业务逻辑的处理。但事实上,在 Easegress v1.x 中,重试、熔断等控制逻辑是通过 Filter 实现的,这就让 Pipeline 不得不使用复杂的责任链模式来调用 Filter,既导致调用逻辑难以理解,也导致某些场景下用户对调用次序的误解。
新版本的重要改进
在 Easegress v2.0 中,我们针对以上问题进行了专门的改进:
多协议支持:为了让 Easegress 的 pipeline 可以支持多协议,我们必需对 pipeline 处理的协议进行抽象。一般来说,协议体中有协议头和负载,协议头基本都是 key-value 形式,用做协议控制,负载基本都是业务相关的内容。所以,我们需要把协议抽象成 Context 上下文。
控制逻辑和业务逻辑分离:Easegress 中的一些与弹力(容错)设计(熔断、超时、重试等)相关的控制逻辑,我们觉得做成 Filter 并不合适,这些逻辑其实都是用来保护后端服务的,v1.x 中的实现方式把控制逻辑和业务逻辑混在一起,非常乱,所以我们在 v2.0 中直接把它们内嵌在了 Proxy 上,这样,整个流程就非常干净了。
强大易用的API编排:这是非常关键的一项改进,网关就是在代理、编排和组合各种 API,所以,我们要提供一个更容易使用,更为强大,不用写代码的 API 流程编排 DSL。 下面,我们用一个例子来演示一下 Easegress v2.0 的 API 编排功能。
API 编排示例
在这个示例中,我们将通过 Easegress (请参考这篇文档提前安装好 Easegress v2.0)实现一个 Telegram 的机器人,它从 Telegram 接收到消息后,会先调用 AWS 的翻译 API 将其翻译为指定的语言,再调用 AWS 的 TTS 引擎 Polly 将翻译结果转换为语音,并返回 Telegram,如下图所示:
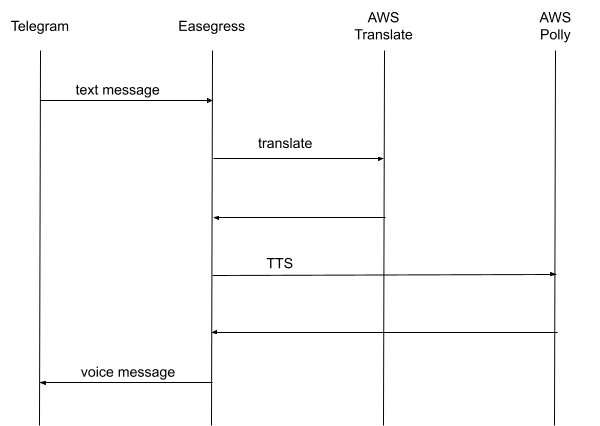
整个过程涉及三次 API 调用(翻译、TTS 和向 Telegram 发消息),并且,后面的调用依赖于前面调用的结果。
需求并不复杂,但就像我们前面提到过的读取 RSS 然后发送到 Slack 一样,Easegress v1.x 无法直接实现这个需求,事实上,Nginx 等其它传统的网关同样也无法直接实现。传统网关能做的,仅仅只是充当一个反向代理,将客户端的请求转发到后端服务。这个过程涉及代码编写、服务部署、对网关进行配置 等多个步骤,技术难度不大,但很繁杂。
而在 Easegress v2.0 中,我们则可以直接通过 API 编排的方式来达到目的,完全不需要编写代码、部署服务。下面,我们就来看具体的做法。
首先,我们需要按照 Telegram 的文档,创建一个机器人(在下面的示例中,机器人的名字是 EaseTranslateBot),并设置好 WebHook,这一部分与 Easegress 关系不大,我们不再赘述。
然后,我们使用一个 RequestBuilder、一个 RequestAdaptor 和一个 Proxy 来翻译 Telegram 发来的文本消息。RequestBuilder 从原始请求中提取出消息文本和目标语言,用它们生成新的 Request,RequestAdaptor 将请求按照 AWS 的要求签名,Proxy 把请求发送出去,并接收翻译结果。由于要符合 AWS 的格式要求,RequestBuilder 的配置有些复杂,这是必须的,用其他方式实现同样的功能的复杂程度也会类似。
filters:
- kind: RequestBuilder
name: requestBuilderTranslate
template: |
{{$msg := or .requests.DEFAULT.JSONBody.message .requests.DEFAULT.JSONBody.channel_post}}
{{if contains "@easetranslatebot" (lower $msg.text)}}
{{$lang := or (trim (replace "@easetranslatebot" "" (lower $msg.text))) "chinese"}}
{{$lang = index .data.PIPELINE (lower $lang)}}
method: POST
url: https://translate.us-east-2.amazonaws.com/TranslateText
headers:
"Content-Type": ["application/x-amz-json-1.1"]
"X-Amz-Target": ["AWSShineFrontendService_20170701.TranslateText"]
body: |
{
"SourceLanguageCode": "auto",
"TargetLanguageCode": "{{$lang.code}}",
"Text": "{{$msg.reply_to_message.text | jsonEscape}}"
}
{{end}}
- name: requestAdaptorTranslate
kind: RequestAdaptor
sign:
apiProvider: aws4
# 请使用你自己的 access key id 和 secret
accessKeyId: AKXXXXXXXXXXXXXXXXXX
accessKeySecret: XYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYY
scopes: ["us-east-2", "translate"]
- name: proxyTranslate
kind: Proxy
pools:
- servers:
- url: https://translate.us-east-2.amazonaws.com
注意,在 RequestBuilder 模板中,我们除了引用了原始 Request 的信息,也使用 了 pipeline 上设置的用户数据来将目标语言从用户友好的形式转成 AWS 翻译引擎语言代码(例如,把用户输入的目标语言 Chinese 转换为 zh)。用户数据是使用如下格式在 pipeline 上设置的(除了目标语言之外,也设置了每种语言使用的语音引擎,用于将文本转为语音)。
data:
chinese:
code: zh
voice: Zhiyu
english:
code: en
voice: Joanna
...
翻译完成以后,我们就需要把翻译后的文本转换为语音,同样需要使用一个 RequestBuilder、一个 RequestAdaptor 和一个 Proxy。
filters:
...
- kind: RequestBuilder
name: requestBuilderPolly
template: |
{{$msg := or .requests.DEFAULT.JSONBody.message .requests.DEFAULT.JSONBody.channel_post}}
{{$lang := or (trim (replace "@easetranslatebot" "" (lower $msg.text))) "chinese"}}
{{$lang = index .data.PIPELINE (lower $lang)}}
method: POST
url: https://polly.us-east-2.amazonaws.com/v1/speech
headers:
"Content-Type": ["application/json"]
body: |
{
"Engine": "standard",
"OutputFormat": "ogg_vorbis",
"Text": "{{.responses.translate.JSONBody.TranslatedText | jsonEscape}}",
"VoiceId": "{{$lang.voice}}"
}
- name: requestAdaptorPolly
kind: RequestAdaptor
sign:
apiProvider: aws4
# 请使用你自己的 access key id 和 secret
accessKeyId: AKXXXXXXXXXXXXXXXXXX
accessKeySecret: XYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYY
scopes: ["us-east-2", "polly"]
- name: proxyPolly
kind: Proxy
pools:
- servers:
- url: https://polly.us-east-2.amazonaws.com
之后,我们再将翻译结果发送到 Telegram,Telegram 不需要签名,所以这一步比前两步少用了一个 RequestAdaptor。
- kind: RequestBuilder
name: requestBuilderTelegram
template: |
{{$msg := or .requests.DEFAULT.JSONBody.message .requests.DEFAULT.JSONBody.channel_post}}
method: POST
# 请使用你自己的机器人的 API 地址
url: https://api.telegram.org/bot0123456789:AABBCCDDEEFFGG-5sijosfjfsjiWVdi743/sendVoice
formData:
chat_id:
value: {{$msg.chat.id}}
reply_to_message_id:
value: {{$msg.reply_to_message.message_id}}
voice:
fileName: "tg.ogg"
value: !!binary "{{.responses.polly.Body | b64enc}}"
- name: proxyTelegram
kind: Proxy
pools:
- servers:
- url: https://api.telegram.org
最后,我们还需要一个 ResponseBuilder 来创建一个对应于最初 Request 的 Response,它的配置很简单这里就省略了。配置好所有的 Filter 后,我们可以用下面的 YAML 把它们编排起来。注意,由于整个处理过程涉及多个 Request 和 Response,所以我们使用了命名空间(namespace),大多数 Filter 只能使用自己命名空间内的 Request 和 Response,但 RequestBuilder 和 ResponseBuilder 可以访问所有 Request 和 Response,详情请参阅后文。
flow:
# 把 ResponseBuilder 放在了最前面,Telegram 要求所有 Request 都必须返回 Response,但我们只处理
# 部分 Request。如果放在最后,我们不处理的那些 Request 会让流程提前结束,导致没有 Response 返回。
- filter: responseBuilder
# 翻译
- filter: requestBuilderTranslate
namespace: translate
- filter: requestAdaptorTranslate
namespace: translate
- filter: proxyTranslate
namespace: translate
# 文本转语音
- filter: requestBuilderPolly
namespace: polly
- filter: requestAdaptorPolly
namespace: polly
- filter: proxyPolly
namespace: polly
# 将语音发送给 Telegram
- filter: requestBuilderTelegram
namespace: tg
- filter: proxyTelegram
namespace: tg
我们把完整的配置(见本文附件)保存为 telegram-pipeline.yaml,然后执行:
$ egctl object create -f telegram-pipeline.yaml
就创建好了 pipeline。
但只有 pipeline 还不够,我们还需要创建一个 HTTPServer,并让它将 telegram 的 Request 转发到上面的 pipeline,注意,这条 pipeline 的外部访问地址,必须是我们前面创建的 Telegram WebHook 的地址。
$ echo '
kind: HTTPServer
name: server-demo
port: 10080
keepAlive: true
https: false
rules:
- paths:
- pathPrefix: /telegram
backend: telegram-pipeline' | egctl object create
之后,用类似下图的方式发送消息,就可以看到机器人的执行结果了,图中的语音消息是机器人发送的,其它消息是我们发送的。
改进细节
为了达到前述的三个目标:多协议支持,控制逻辑和业务逻辑解耦,以及强大易用的API编排,我们进行了如下的改进。
首先,我们明确界定了三个核心对象 Context、Filter 和 Pipeline 的功能:
- Context 是一个数据容器,Request 和 Response 是其中的数据,数据可以协议相关,但容器必须协议无关;
- Filter 对数据进行处理,既可以协议相关,也可以协议无关,但必须专注于业务逻辑;
- Pipeline 对 Filter 进行编排,专注于实现控制逻辑,必须协议无关。
第二,删除了容错相关的 Filter(Retryer、CircuitBreaker 和 TimeLimiter),改为在 Pipeline 上定义容错策略,然后 Filter 可以实现 Resiliencer 接口。如果某个 Filter 实现了 Resiliencer 接口,Pipeline 在创建这个 Filter 时,会向其中注入容错策略。
第三,v1.x 中,每个 Context 只能保存至多一个 Request 和一个 Response,为了支持复杂 API 编排,v2.0 中的 Context 被划分成了多个命名空间(namespace),每个命名空间可以保存一个 Request 和 一个 Response。同时,在定义 Pipeline 时,可以为每个 Filter 指定一个命名空间,多数 Filter 只能使用该命名空间中的 Request 和 Response。最后,我们新实现了 RequestBuilder 和 ResponseBuilder 两个 Filter 来突破命名空间的限制,这两个 Filter 都可以访问 Context 中的所有数据,然后将生成的 Request 或 Response 保存到指定的命名空间中(如下图所示,其中,DEFAULT、slack 是命名空间)。

以上这些改进,不仅解决了 v1.x 中存在的问题,也大幅增强了流量编排的灵活性,让 Easegress 具有了实现类似工作流等业务逻辑的处理的能力,提供了另一种扩展业务逻辑的方法。
新 Pipeline DSL
为了反映设计和实现上的改进,Pipeline DSL 也进行了调整和优化。
1. Pipeline
Pipeline 不再按协议进行区分:
name: demo-pipeline
kind: Pipeline # 统一使用 Pipeline,不再使用 HTTPPipeline 等
2. 容错策略
Pipeline 中增加了容错策略相关定义:
filters:
- kind: Proxy
name: proxy
pools:
- servers:
...
timeout: 500ms
retryPolicy: retry3Times # 引用重试策略
circuitBreakerPolicy: circuitBreakAfter10Failure # 引用熔断策略
...
resilience: # 新增加的部分,定义容错策略
- name: retry3Times
kind: RetryPolicy
maxAttempts: 3
...
- name: circuitBreakAfter10Failure
kind: CircuitBreakerPolicy
...
3. 用户数据
Pipeline 中可以设置用户数据。
这些数据既可以在 filter 中使用代码引用,也可以在 RequestBuilder / ResponseBuilder 的模板中使用如 .data.PIPELINE.chinese.voice 的形式引用。
filters:
- kind: Proxy
name: proxy
...
data:
chinese:
code: zh
voice: Zhiyu
english:
code: en
voice: Joanna
4. 命名空间(namespace)
Filter 可以通过 namespace 指定其所属的命名空间,默认命名空间是 DEFAULT。
flow:
- filter: validator
- filter: buildRssRequest
namespace: rss # v2.0 新增
5. 内置 Filter END
可以使用 END Filter 直接结束处理流程,END 是内置 Filter,无需定义,可以直接使用。
flow:
- filter: validator
jumpIf:
invalid: buildFailureResponse
- filter: proxy
- filter: END # 结束处理
- filter: buildFailureResponse
6. 别名(alias)
在下面的处理流程中,Filter mockRequest 出现了两次,通过使用别名,我们可以明确指定 validator 校验失败后的跳转目标:
flow:
- filter: validator
jumpIf:
invalid: mockRequestForProxy2 # 使用别名进行跳转
- filter: mockRequest
- filter: proxy1
- filter: END
- filter: mockRequest
alias: mockRequestForProxy2 # 为 mockRequest 指定了别名
- filter: proxy2
7. RequestBuilder 和 ResponseBuilder
RequestBuilder 和 ResponseBuilder 可以在目标命名空间中创建已有 Request 或 Response 的引用,也可以使用模板创建全新的 Request 或 Response。它们使用的模板是基于 Go 语言标准库中的 text/template 实现的,同时加入了 sprig 中的辅助函数。
kind: HTTPRequestBuilder
name: buildSlackRequest
sourceNamespace: rss # 不能同时使用 sourceNamespace 和 template
template: |
method: POST
url: /services/TXXXXXXX/BXXXXXXXXX/xyxyxyxyxyxyxyxyxyxyxy
body: |
{
"text": "近期文章 - {{.responses.rss.JSONBody.title}}",
"blocks": [{
"type": "section",
"text": {
"type": "plain_text",
"text": "近期文章 - {{.responses.rss.JSONBody.title}}"
}
}, {
"type": "section",
"text": {
"type": "mrkdwn",
"text": "{{range $index, $item := .responses.rss.JSONBody.items}}• <{{$item.url}}|{{$item.title}}>\n{{end}}"
}}]
}
迁移 v1.x Filter 到 v2.0
由于 v2.0 的改进很多,所以它与 v1.x 并不完全兼容,为 v1.x 开发的 Filter 需要进行一些修改才能融入 v2.0,具体请参阅迁移说明。
附件 - Telegram Pipeline 的完整配置
name: telegram-pipeline
kind: Pipeline
flow:
# we put the ResponseBuilder at the top because Telegram requires us to return a response for
# every Request, but we only process some of the requests. If we put it at the end, the
# requests we don't process will end the process early and no Response will be returned.
- filter: responseBuilder
# translation
- filter: requestBuilderTranslate
namespace: translate
- filter: requestAdaptorTranslate
namespace: translate
- filter: proxyTranslate
namespace: translate
# text to speech
- filter: requestBuilderPolly
namespace: polly
- filter: requestAdaptorPolly
namespace: polly
- filter: proxyPolly
namespace: polly
# send the voice message to Telegram
- filter: requestBuilderTelegram
namespace: tg
- filter: proxyTelegram
namespace: tg
data:
chinese:
code: zh
voice: Zhiyu
english:
code: en
voice: Joanna
french:
code: fr
voice: Léa
japanese:
code: ja
voice: Mizuki
korean:
code: ko
voice: Seoyeon
german:
code: de
voice: Vicki
spanish:
code: es
voice: Lucia
arabic:
code: ar
voice: Zeina
dutch:
code: nl
voice: Lotte
italian:
code: it
voice: Carla
polish:
code: pl
voice: Ewa
filters:
- kind: RequestBuilder
name: requestBuilderTranslate
template: |
{{$msg := or .requests.DEFAULT.JSONBody.message .requests.DEFAULT.JSONBody.channel_post}}
{{if contains "@easetranslatebot" (lower $msg.text)}}
{{$lang := or (trim (replace "@easetranslatebot" "" (lower $msg.text))) "chinese"}}
{{$lang = index .data.PIPELINE (lower $lang)}}
method: POST
url: https://translate.us-east-2.amazonaws.com/TranslateText
headers:
"Content-Type": ["application/x-amz-json-1.1"]
"X-Amz-Target": ["AWSShineFrontendService_20170701.TranslateText"]
body: |
{
"SourceLanguageCode": "auto",
"TargetLanguageCode": "{{$lang.code}}",
"Text": "{{$msg.reply_to_message.text | jsonEscape}}"
}
{{end}}
- name: requestAdaptorTranslate
kind: RequestAdaptor
sign:
apiProvider: aws4
# Please use your own access key & secret
accessKeyId: AKXXXXXXXXXXXXXXXXXX
accessKeySecret: XYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYY
scopes: ["us-east-2", "translate"]
- name: proxyTranslate
kind: Proxy
pools:
- servers:
- url: https://translate.us-east-2.amazonaws.com
- kind: RequestBuilder
name: requestBuilderPolly
template: |
{{$msg := or .requests.DEFAULT.JSONBody.message .requests.DEFAULT.JSONBody.channel_post}}
{{$lang := or (trim (replace "@easetranslatebot" "" (lower $msg.text))) "chinese"}}
{{$lang = index .data.PIPELINE (lower $lang)}}
method: POST
url: https://polly.us-east-2.amazonaws.com/v1/speech
headers:
"Content-Type": ["application/json"]
body: |
{
"Engine": "standard",
"OutputFormat": "ogg_vorbis",
"Text": "{{.responses.translate.JSONBody.TranslatedText | jsonEscape}}",
"VoiceId": "{{$lang.voice}}"
}
- name: requestAdaptorPolly
kind: RequestAdaptor
sign:
apiProvider: aws4
# Please use your own access key & secret
accessKeyId: AKXXXXXXXXXXXXXXXXXX
accessKeySecret: XYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYY
scopes: ["us-east-2", "polly"]
- name: proxyPolly
kind: Proxy
pools:
- servers:
- url: https://polly.us-east-2.amazonaws.com
- kind: RequestBuilder
name: requestBuilderTelegram
template: |
{{$msg := or .requests.DEFAULT.JSONBody.message .requests.DEFAULT.JSONBody.channel_post}}
method: POST
# Please replace it with the url of your bot
url: https://api.telegram.org/bot0123456789:AABBCCDDEEFFGG-5sijosfjfsjiWVdi743/sendVoice
formData:
chat_id:
value: {{$msg.chat.id}}
reply_to_message_id:
value: {{$msg.reply_to_message.message_id}}
voice:
fileName: "tg.ogg"
value: !!binary "{{.responses.polly.Body | b64enc}}"
- name: proxyTelegram
kind: Proxy
pools:
- servers:
- url: https://api.telegram.org
- kind: ResponseBuilder
name: responseBuilder
template: |
statusCode: 200
``